参考中国报告网发布《2017-2022年中国人工智能行业运营现状及盈利战略分析报告》
人工智能芯片,目前有两种发展路径:一种是延续传统计算架构,加速硬件计算能力,主要以 3 种类型的芯片为代表,即 GPU、FPGA 和 ASIC,但 CPU 依旧发挥着不可替代的作用;另一种是颠覆经典的冯诺依曼计算架构,采用人脑神经元的结构来提升计算能力,以 IBM TrueNorth 芯片为代表。由于人脑神经元芯片距离产业化仍然较远,我们着重讨论在人工智能时代 GPU,FPGA 和 ASIC 的应用和未来发展可能性。
按照处理器芯片的效率排序,从低到高依次是 CPU、DSP、GPU、FPGA和 ASIC。沿着 CPU->ASIC 的方向,芯片中晶体管的效率越来越高。因为 FPGA&ASIC 等芯片实现的算法直接用晶体管门电路实现,比起指令系统,算法直接建筑在物理结构之上,没有中间层次,因此晶体管的效率最高。CPU&GPU 需要软件支持,而 FPGA&ASIC 则是软硬件一体的架构,软件就是硬件。
而按照晶体管易用性排序是相反的。从 ASIC 到 CPU,芯片的易用性越来越强。 CPU&GPU 的编程需要编译系统的支持,编译系统的作用是把高级软件语言翻译成机器可以识别的指令(也叫机器语言)。高级语言带来了极大的便利性和易用性,因此用 CPU&GPU 实现同等功能的软件开发周期要远低于 FPGA&ASIC 芯片。

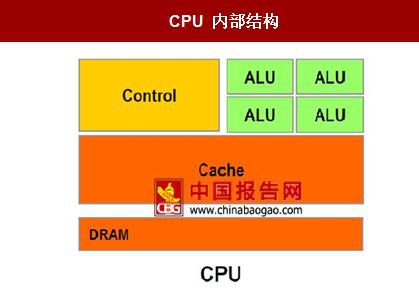
CPU 作为通用处理器,兼顾计算和控制,70%晶体管用来构建 Cache 还有一部分控制单元,用来处理复杂逻辑和提高指令的执行效率,如图所示,所以导致计算通用性强,可以处理计算复杂度高,但计算性能一般。目前,英特尔等芯片制造商主要通过增加 CPU 核数来增加计算能力,但是因为每个物理核中只有 30%的晶体管是计算单元。通过这种方式来增加计算能力并不划算,还带来芯片功耗和价格的增加。
此外,英特尔进行 CPU 架构调整的时间也在放缓。原来英特尔按照“Tick-Tock”二年一个周期进行 CPU 架构调整,从 2016 年开始放缓至三年,更新迭代周期较长。
由此可见,CPU 仍然最好的通用处理器之一,但是在高性能计算上,CPU 越来越无
法满足计算能力提升的需求。
GPU 主要擅长做类似图像处理的并行计算,所谓的“粗粒度并行(coarse-grain parallelism)”。图形处理计算的特征表现为高密度的计算而计算需要的数据之间较少存在相关性,GPU 提供大量的计算单元(多达几千个计算单元)和大量的高速内存,可以同时对很多像素进行并行处理。
GPU 的设计出发点就是用于计算强度高、多并行的计算。GPU 把晶体管更多用于计算单元,而不像 CPU 用于数据 Cache 和流程控制器。GPU 中逻辑控制单元不需要能够快速处理复杂控制。并行计算时,每个数据单元执行相同程序,不需要繁琐的流程控制而更需要高计算能力,因此也不需要大的 cache 容量。
GPU 同 CPU 一样也是指令执行过程:取指令->指令译码->指令执行,只有在指令执行的时候,计算单元才发挥作用。GPU 的逻辑控制单元相比 CPU 简单,要想做到指令流水处理,提高指令执行效率,必然要求处理的算法本身复杂度低,处理的数据之间相互独立,所以算法本身的串行处理会导致 GPU 浮点计算能力的显著降低。
GPU 具有最强大的并行计算处理能力。以 GP100 为例,其双精度运算能力是5.3Teraflops,单精度为 10.6Teraflops(AMD 双芯 Radeon Pro Duo 是 16 TeraFLOPs)。
而英伟达在开发者大会GTC2017上发布新一代GPU架构Volta,首款核心为GV100,据称其在推理场景下,V100 比上一代搭载 GP100 CPU 的 P100 板卡,图像处理能力提升了约 10 倍,延迟也下降了约 30%。

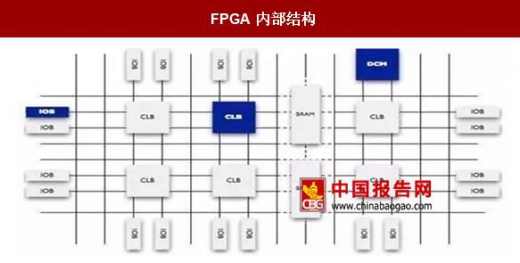
FPGA 即现场可编程门阵列,它不采用指令和软件,是软硬件合一的器件。FPGA 由于算法是定制的,没有 CPU 和 GPU 的取指令和指令译码过程,数据流直接根据定制的算法进行固定操作,计算单元在每个时钟周期上都可以执行,所以可以充分发挥浮点计算能力,计算效率高于 CPU 和 GPU。
整个 FPGA 市场规模约 50 亿美元。由于 FPGA 万能芯片的特点,它被芯片厂商用作芯片原型设计和验证,还广泛使用在通讯密集型和计算密集型市场中,使用行业包括通讯、军工、汽车电子、消费及医疗等行业。
FPGA 的缺点在于进行编程要使用硬件描述语言,而掌握硬件描述语言的人才太少,限制了其使用的拓展。
ASIC:高性能功耗比的专用芯片
ASIC 是一种专用芯片,与传统的通用芯片有一定的差异。是为了某种特定的需求而专门定制的芯片。ASIC 芯片的计算能力和计算效率都可以根据算法需要进行定制,所以 ASIC 与通用芯片相比,具有以下几个方面的优越性:体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低。但是缺点也很明显:算法是固定的,一旦算法变化就可能无法使用。
与 FPGA 相比,ASIC 上市速度慢,需要大量时间开发,而且一次性成本(光刻掩模制作成本)远高于 FPGA,但是性能高于 FPGA 且量产后平均成本低于 FPGA。在同一时间点上用最好的工艺实现的ASIC的加速器的速度会比用同样工艺FPGA做的加速器速度快 5-10 倍,而且一旦量产后 ASIC 的成本会远远低于 FPGA 方案。

人工智能芯片,目前有两种发展路径:一种是延续传统计算架构,加速硬件计算能力,主要以 3 种类型的芯片为代表,即 GPU、FPGA 和 ASIC,但 CPU 依旧发挥着不可替代的作用;另一种是颠覆经典的冯诺依曼计算架构,采用人脑神经元的结构来提升计算能力,以 IBM TrueNorth 芯片为代表。由于人脑神经元芯片距离产业化仍然较远,我们着重讨论在人工智能时代 GPU,FPGA 和 ASIC 的应用和未来发展可能性。
按照处理器芯片的效率排序,从低到高依次是 CPU、DSP、GPU、FPGA和 ASIC。沿着 CPU->ASIC 的方向,芯片中晶体管的效率越来越高。因为 FPGA&ASIC 等芯片实现的算法直接用晶体管门电路实现,比起指令系统,算法直接建筑在物理结构之上,没有中间层次,因此晶体管的效率最高。CPU&GPU 需要软件支持,而 FPGA&ASIC 则是软硬件一体的架构,软件就是硬件。
而按照晶体管易用性排序是相反的。从 ASIC 到 CPU,芯片的易用性越来越强。 CPU&GPU 的编程需要编译系统的支持,编译系统的作用是把高级软件语言翻译成机器可以识别的指令(也叫机器语言)。高级语言带来了极大的便利性和易用性,因此用 CPU&GPU 实现同等功能的软件开发周期要远低于 FPGA&ASIC 芯片。
处理器芯片对比

资料来源:中国报告网整理
CPU 仍然是最好的通用处理器之一 CPU 作为通用处理器,兼顾计算和控制,70%晶体管用来构建 Cache 还有一部分控制单元,用来处理复杂逻辑和提高指令的执行效率,如图所示,所以导致计算通用性强,可以处理计算复杂度高,但计算性能一般。目前,英特尔等芯片制造商主要通过增加 CPU 核数来增加计算能力,但是因为每个物理核中只有 30%的晶体管是计算单元。通过这种方式来增加计算能力并不划算,还带来芯片功耗和价格的增加。
此外,英特尔进行 CPU 架构调整的时间也在放缓。原来英特尔按照“Tick-Tock”二年一个周期进行 CPU 架构调整,从 2016 年开始放缓至三年,更新迭代周期较长。
由此可见,CPU 仍然最好的通用处理器之一,但是在高性能计算上,CPU 越来越无
法满足计算能力提升的需求。
CPU 内部结构

资料来源:中国报告网整理
GPU 具有最强大的并行计算能力 GPU 主要擅长做类似图像处理的并行计算,所谓的“粗粒度并行(coarse-grain parallelism)”。图形处理计算的特征表现为高密度的计算而计算需要的数据之间较少存在相关性,GPU 提供大量的计算单元(多达几千个计算单元)和大量的高速内存,可以同时对很多像素进行并行处理。
GPU 的设计出发点就是用于计算强度高、多并行的计算。GPU 把晶体管更多用于计算单元,而不像 CPU 用于数据 Cache 和流程控制器。GPU 中逻辑控制单元不需要能够快速处理复杂控制。并行计算时,每个数据单元执行相同程序,不需要繁琐的流程控制而更需要高计算能力,因此也不需要大的 cache 容量。
GPU 同 CPU 一样也是指令执行过程:取指令->指令译码->指令执行,只有在指令执行的时候,计算单元才发挥作用。GPU 的逻辑控制单元相比 CPU 简单,要想做到指令流水处理,提高指令执行效率,必然要求处理的算法本身复杂度低,处理的数据之间相互独立,所以算法本身的串行处理会导致 GPU 浮点计算能力的显著降低。
GPU 具有最强大的并行计算处理能力。以 GP100 为例,其双精度运算能力是5.3Teraflops,单精度为 10.6Teraflops(AMD 双芯 Radeon Pro Duo 是 16 TeraFLOPs)。
而英伟达在开发者大会GTC2017上发布新一代GPU架构Volta,首款核心为GV100,据称其在推理场景下,V100 比上一代搭载 GP100 CPU 的 P100 板卡,图像处理能力提升了约 10 倍,延迟也下降了约 30%。
GPU 内部结构

资料来源:中国报告网整理
FPGA:万能芯片 FPGA 即现场可编程门阵列,它不采用指令和软件,是软硬件合一的器件。FPGA 由于算法是定制的,没有 CPU 和 GPU 的取指令和指令译码过程,数据流直接根据定制的算法进行固定操作,计算单元在每个时钟周期上都可以执行,所以可以充分发挥浮点计算能力,计算效率高于 CPU 和 GPU。
FPGA 内部结构

资料来源:中国报告网整理
整个 FPGA 市场规模约 50 亿美元。由于 FPGA 万能芯片的特点,它被芯片厂商用作芯片原型设计和验证,还广泛使用在通讯密集型和计算密集型市场中,使用行业包括通讯、军工、汽车电子、消费及医疗等行业。
FPGA 的缺点在于进行编程要使用硬件描述语言,而掌握硬件描述语言的人才太少,限制了其使用的拓展。
ASIC:高性能功耗比的专用芯片
ASIC 是一种专用芯片,与传统的通用芯片有一定的差异。是为了某种特定的需求而专门定制的芯片。ASIC 芯片的计算能力和计算效率都可以根据算法需要进行定制,所以 ASIC 与通用芯片相比,具有以下几个方面的优越性:体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低。但是缺点也很明显:算法是固定的,一旦算法变化就可能无法使用。
与 FPGA 相比,ASIC 上市速度慢,需要大量时间开发,而且一次性成本(光刻掩模制作成本)远高于 FPGA,但是性能高于 FPGA 且量产后平均成本低于 FPGA。在同一时间点上用最好的工艺实现的ASIC的加速器的速度会比用同样工艺FPGA做的加速器速度快 5-10 倍,而且一旦量产后 ASIC 的成本会远远低于 FPGA 方案。
ASIC 与 FPGA 对比

资料来源:中国报告网整理
资料来源:中国报告网整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








