NVIDIA 英伟达
从 PC 时代的“显卡之王”到人工智能时代的计算领导者。NVIDIA 在 1999 年发明了 GPU,推动了 PC 游戏市场的发展,重新定义了现代计算机图形技术,并彻底改变了并行计算。公司凭借卓越的技术和产品性能市场占有率一度高达 70%,是 PC 时代无可争议的“显卡之王”。随着人工智能技术的飞速进步,GPU 并行计算在人工智能深度神经网络训练中的强大威力被发掘出来,NVIDIA 公司亦开始在人工智能计算、无人驾驶、智能机器人和物联网等领域进行深入布局,向人工智能时代的计算领导者转型。NVIDIA 的 GPU 计算技术和产品演进历史。
2006 年,NVIDIA 的 CUDA 编程模型与 Tesla GPU 平台的问世将 GPU 的并行计算功能引入到通用计算领域。一种强大而又全新的计算方式就此诞生。
2010 年,世界各地的人工智能研究人员已经开始利用 NVIDIA GPU 的并行计算能力来进行神经网络训练。
2012 年,多伦多大学 Alex Krizhevsky 利用NVIDIA GPU 训练的深度神经网络在ImageNet 图像识别挑战赛中成功胜出,击败了全部有着数十年算法经验的专家;同年,斯坦福大学的吴恩达 (Andrew Ng)与 NVIDIA 研究院展开合作开发了一种利用大规模 GPU 计算系统来进行网络训练的方法。
2016 年,NVIDIA 公布了用于人工智能的最新款 Tesla P100 芯片,该款芯片内置 150 亿个晶体管是当时全球最大的 FinFET 芯片,其研发费用高达 20 亿美元。用于深度学习的型号为 DGX-1 的超级计算机同时被推出,这款售价 12.9 万美元的计算机拥有 7 TB 的 SSD 存储,8 块上述的 Tesla P100 GPU 和两个 Xeon 处理器,相当于集成了 250 个服务器,整台设备是 2015 年发布的超级计算机运算能力的 12 倍。
2017 年,NVIDIA 发布了面向人工智能和高性能并行计算的 Tesla V100 处理器。Tesla V100 搭载的 GV100 GPU 基于台积电的最新 12nm FFN 高精度制程封装技术,在 815 平方毫米的芯片中集成了 640 个 Tensor cores、211 亿个晶体管,是世界上第一款突破 100 TFLOPS 的 GPU 产品,比 Tesla P100 快 1.5 倍。GV100 GPU 还具有一系列的硬件创新,包括进一步精简的 GPU 编程和应用部署流程以及为深度学习算法和框架、HPC 系统和应用程序提供的强大计算支持。再结合新一代 NVIDIA NVLink 技术高达 300 GB/s 的连接能力,现实场景中用户可以将多个 V100 GPU 组合起来搭建成强大的深度学习运算中心。
2017 年财报靓丽,人工智能新业务前景可期,股价表现强劲。受益于人工智能和大数据产业发展,2016 年以来 NVIDIA 的数据中心以及智能驾驶业务表现十分突出:数据中心业务 2016 年收入 8.3 亿美元同比增长 145%,2017 年中报显示,该业务收入更是达到了 8.25 亿美元,同比增长 181%;智能驾驶业务 2016 年收入 4.87 亿美元,同比增长 52%,2017年中报收入 2.82 亿美元,同比增长 22%。同时占全公司收入近 60%的游戏业务持续保持快速增长,公司 2016 年整体收入 69.1 亿美元,利润 16.66 亿美元,同比增长分别为 38%和171%,2017 年中报整体收入 41.67 亿美元,利润 10.91 亿美元,同比增长分别为 52%和133%,财务报表十分靓丽。2016 年 1 月以来公司股价累计上涨超过了 450%,是标准普尔 500 指数表现强劲的成分股之一。

AMD(ATI)
参考中国报告网发布《2016-2022年中国图形处理器(GPU)行业现状调查及竞争策略分析报告》
2016 年底,AMD 推出了结合硬件和开源软件方案的 Radeon Instinct 平台。Radeon Instinct 加速器为客户提供基于 GPU 的深度学习算法解决方案。Radeon Instinct 是针对机器智能的开放软件生态系统的蓝图,有助于加速推理洞察和算法训练,它采用被动式散热、符合 SR-IOV(单根 I / O 虚拟化)行业标准的 AMD MultiGPU(MxGPU)硬件虚拟化技术,并且具有大基址寄存器和 64-bit PCIe 寻址功能,支持多 GPU 点对点运行。于此同时,AMD宣布推出 MIOpen——一款用于 GPU 加速器的免费开源库,用于为卷积、池化、激活函数,归一化和张量格式等标准例程提供 GPU 优化,从而实施高性能的机器智能,为机器智能持续进化提供基础。
2017 年,AMD 开始和竞争对手 Intel 展开合作,在 Intel 的 CPU 上集成 AMD 的 Radeon GPU。这款 Intel 的代号为“Kaby Lake-G”的处理器,CPU 部分通过 PCI-E x8 通道连接独立的 GPU 芯片,并且还带有 HBM2 高带宽显存。GPU 部分是个单独的芯片,通过 MCM 方式与 Kaby Lake 处理器整合封装在一起,Intel 标注它是个“2-chip”样式的产品。

2017 年 1 月,AMD 公布了最新的 Vega GPU 架构,2017 年 8 月,基于代号 Vega 织女星的新一代 RADEON RX VEGA64 GPU 正式发布,在各项测试和应用中性能超过英伟达Pascal 系列,在 Deep Bench 中的跑分是英伟达 Tesla P100 显卡的 1.38-1.51 倍,Vega凭借强劲的性能,有望和 NVIDIA Pascal GP10x 甚至是下一代的 Volta 正面对决。

早在 2011 年,AMD 就推出了 CPU+GPU 的异构计算方案 APU。不管 CPU 还是 GPU,所有人都在追求性能,但性能受制于半导体制造工艺的限制,又不能无限制的提升,否则功耗和成本就无法控制,应用领域会受到严重的限制。所以现在很多人都看重“每瓦性能”,或者是说效率。APU 就是一种智能计算架构,通过无缝地分配相应的任务至适合的处理单元,使 CPU、GPU 和其他处理器和谐工作在单一芯片上。AMD 下一代 APU 代号 Raven Ridge,以 Ryzen CPU + Vega GPU 为基础架构打造,Ryzen APU 将配备 4 核 8 线程 Ryzen CPU 核心,而且流处理器单元也会提升到 768 个,再加上 DDR4 内存,官方称 CPU 性能提升 50%,GPU 性能提升 40%,功耗降低 50%,综合性能以及能效会比之前的 APU 会提升一个等级,在 AI 时代 AMD 异构计算 APU 架构将会占据市场重要位置。

从 PC 时代的“显卡之王”到人工智能时代的计算领导者。NVIDIA 在 1999 年发明了 GPU,推动了 PC 游戏市场的发展,重新定义了现代计算机图形技术,并彻底改变了并行计算。公司凭借卓越的技术和产品性能市场占有率一度高达 70%,是 PC 时代无可争议的“显卡之王”。随着人工智能技术的飞速进步,GPU 并行计算在人工智能深度神经网络训练中的强大威力被发掘出来,NVIDIA 公司亦开始在人工智能计算、无人驾驶、智能机器人和物联网等领域进行深入布局,向人工智能时代的计算领导者转型。NVIDIA 的 GPU 计算技术和产品演进历史。
2006 年,NVIDIA 的 CUDA 编程模型与 Tesla GPU 平台的问世将 GPU 的并行计算功能引入到通用计算领域。一种强大而又全新的计算方式就此诞生。
2010 年,世界各地的人工智能研究人员已经开始利用 NVIDIA GPU 的并行计算能力来进行神经网络训练。
2012 年,多伦多大学 Alex Krizhevsky 利用NVIDIA GPU 训练的深度神经网络在ImageNet 图像识别挑战赛中成功胜出,击败了全部有着数十年算法经验的专家;同年,斯坦福大学的吴恩达 (Andrew Ng)与 NVIDIA 研究院展开合作开发了一种利用大规模 GPU 计算系统来进行网络训练的方法。
2016 年,NVIDIA 公布了用于人工智能的最新款 Tesla P100 芯片,该款芯片内置 150 亿个晶体管是当时全球最大的 FinFET 芯片,其研发费用高达 20 亿美元。用于深度学习的型号为 DGX-1 的超级计算机同时被推出,这款售价 12.9 万美元的计算机拥有 7 TB 的 SSD 存储,8 块上述的 Tesla P100 GPU 和两个 Xeon 处理器,相当于集成了 250 个服务器,整台设备是 2015 年发布的超级计算机运算能力的 12 倍。
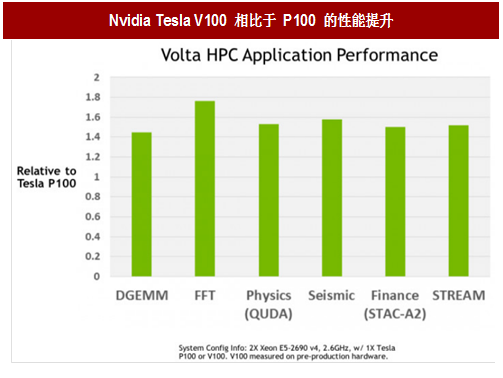
2017 年,NVIDIA 发布了面向人工智能和高性能并行计算的 Tesla V100 处理器。Tesla V100 搭载的 GV100 GPU 基于台积电的最新 12nm FFN 高精度制程封装技术,在 815 平方毫米的芯片中集成了 640 个 Tensor cores、211 亿个晶体管,是世界上第一款突破 100 TFLOPS 的 GPU 产品,比 Tesla P100 快 1.5 倍。GV100 GPU 还具有一系列的硬件创新,包括进一步精简的 GPU 编程和应用部署流程以及为深度学习算法和框架、HPC 系统和应用程序提供的强大计算支持。再结合新一代 NVIDIA NVLink 技术高达 300 GB/s 的连接能力,现实场景中用户可以将多个 V100 GPU 组合起来搭建成强大的深度学习运算中心。

图:Nvidia Tesla V100 相比于 P100 的性能提升
2017 年财报靓丽,人工智能新业务前景可期,股价表现强劲。受益于人工智能和大数据产业发展,2016 年以来 NVIDIA 的数据中心以及智能驾驶业务表现十分突出:数据中心业务 2016 年收入 8.3 亿美元同比增长 145%,2017 年中报显示,该业务收入更是达到了 8.25 亿美元,同比增长 181%;智能驾驶业务 2016 年收入 4.87 亿美元,同比增长 52%,2017年中报收入 2.82 亿美元,同比增长 22%。同时占全公司收入近 60%的游戏业务持续保持快速增长,公司 2016 年整体收入 69.1 亿美元,利润 16.66 亿美元,同比增长分别为 38%和171%,2017 年中报整体收入 41.67 亿美元,利润 10.91 亿美元,同比增长分别为 52%和133%,财务报表十分靓丽。2016 年 1 月以来公司股价累计上涨超过了 450%,是标准普尔 500 指数表现强劲的成分股之一。

图:英伟达近十年来年报业绩表现
AMD(ATI)
ATI 是与英伟达齐名的显卡制造商,2006 年被 AMD 以 54 亿美元收购。ATI(ArrayTechnology Industry)在 1985 年至 2006 年之间是全球重要的显示芯片公司,总部设在加拿大安大略省万锦,上述时间段内,公司在美洲、欧洲和亚洲等地曾拥有超过 3,700 名员工,年营业额在 20 亿美元左右,是一家专门设计与销售适用于个人电脑的显示卡、图形处理器、芯片组、机顶盒、数字电视、电子游戏机和手提式设备等的半导体公司。2006年被美国 AMD 公司以 54 亿美元的巨资收购后成为 AMD 的一部分。收购 ATI 后的 AMD 在 GPU 市场与 NVIDIA 两分天下,2017 年一季度占有约 30%市场份额。
AMD 的 GPU 产品和技术布局参考中国报告网发布《2016-2022年中国图形处理器(GPU)行业现状调查及竞争策略分析报告》
2016 年底,AMD 推出了结合硬件和开源软件方案的 Radeon Instinct 平台。Radeon Instinct 加速器为客户提供基于 GPU 的深度学习算法解决方案。Radeon Instinct 是针对机器智能的开放软件生态系统的蓝图,有助于加速推理洞察和算法训练,它采用被动式散热、符合 SR-IOV(单根 I / O 虚拟化)行业标准的 AMD MultiGPU(MxGPU)硬件虚拟化技术,并且具有大基址寄存器和 64-bit PCIe 寻址功能,支持多 GPU 点对点运行。于此同时,AMD宣布推出 MIOpen——一款用于 GPU 加速器的免费开源库,用于为卷积、池化、激活函数,归一化和张量格式等标准例程提供 GPU 优化,从而实施高性能的机器智能,为机器智能持续进化提供基础。
2017 年,AMD 开始和竞争对手 Intel 展开合作,在 Intel 的 CPU 上集成 AMD 的 Radeon GPU。这款 Intel 的代号为“Kaby Lake-G”的处理器,CPU 部分通过 PCI-E x8 通道连接独立的 GPU 芯片,并且还带有 HBM2 高带宽显存。GPU 部分是个单独的芯片,通过 MCM 方式与 Kaby Lake 处理器整合封装在一起,Intel 标注它是个“2-chip”样式的产品。

图:“Kaby Lake-G”处理器
2017 年 1 月,AMD 公布了最新的 Vega GPU 架构,2017 年 8 月,基于代号 Vega 织女星的新一代 RADEON RX VEGA64 GPU 正式发布,在各项测试和应用中性能超过英伟达Pascal 系列,在 Deep Bench 中的跑分是英伟达 Tesla P100 显卡的 1.38-1.51 倍,Vega凭借强劲的性能,有望和 NVIDIA Pascal GP10x 甚至是下一代的 Volta 正面对决。

图:AMD 最新 Vega GPU 性能测试
早在 2011 年,AMD 就推出了 CPU+GPU 的异构计算方案 APU。不管 CPU 还是 GPU,所有人都在追求性能,但性能受制于半导体制造工艺的限制,又不能无限制的提升,否则功耗和成本就无法控制,应用领域会受到严重的限制。所以现在很多人都看重“每瓦性能”,或者是说效率。APU 就是一种智能计算架构,通过无缝地分配相应的任务至适合的处理单元,使 CPU、GPU 和其他处理器和谐工作在单一芯片上。AMD 下一代 APU 代号 Raven Ridge,以 Ryzen CPU + Vega GPU 为基础架构打造,Ryzen APU 将配备 4 核 8 线程 Ryzen CPU 核心,而且流处理器单元也会提升到 768 个,再加上 DDR4 内存,官方称 CPU 性能提升 50%,GPU 性能提升 40%,功耗降低 50%,综合性能以及能效会比之前的 APU 会提升一个等级,在 AI 时代 AMD 异构计算 APU 架构将会占据市场重要位置。

图:AMD APU 功能示意
资料来源:中国报告网整理,转载请注明出处(GQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








